
How One App Held an Availability Group Hostage
by Michal Kovaľ on 25/05/2021In the world of SQL Server, TEMPDB is often called the "public dumping ground." We expect it to be busy, but we also expect it to clean up after itself.
Read moreThis is one of our tuning successes, particularly for the nightly process of loading data into a report server from the main database. Quite a basic change had a significant impact saving a lot of resources making the process much faster more stable and at the end of the day making our customers happier making them worry less about it.
We knew the exact code that needs to be tuned and we also had access to the test environment where we have done our analysis and test runs.
The solution consisted of 2 covering indexes for the disk tables, which were missing by the data load.
The process uses a temp table to load the main data and then run a few calculations.
The originally used clause
SELECT column1,
column2
INTO #temptable
FROM diskBasedTablewas replaced by the best practice solution (although lazy developers don’t like it) to create the temp table using proper column declaration.
What else we have done:
The changes resulted in the following changes in the execution plan (please consider it only as a highlight of the changes, can’t make it any better to view).
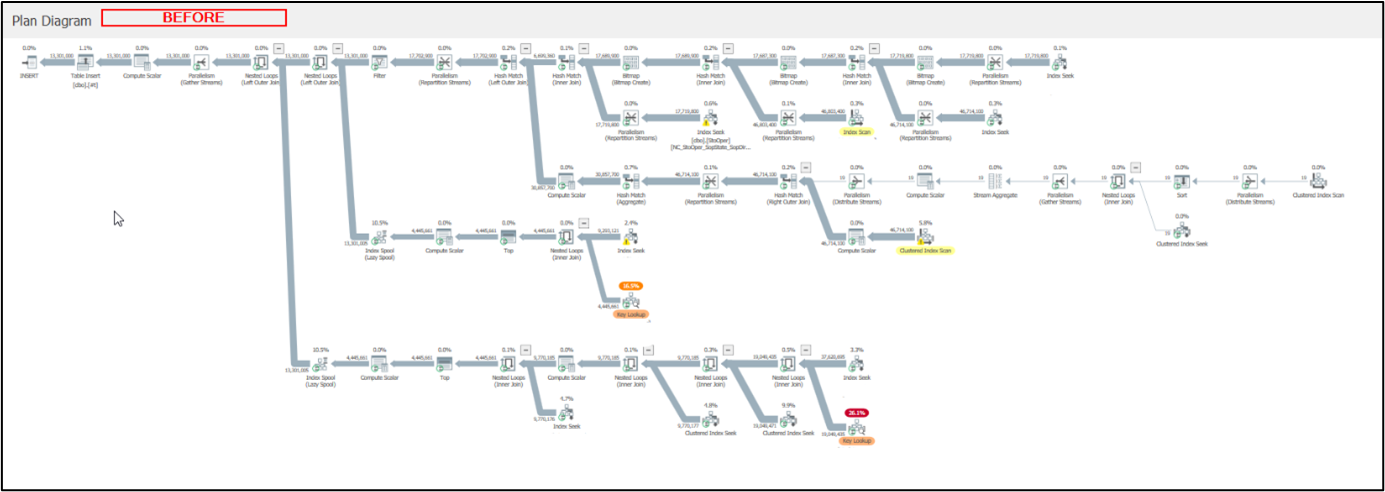
Figure 1: Original plan


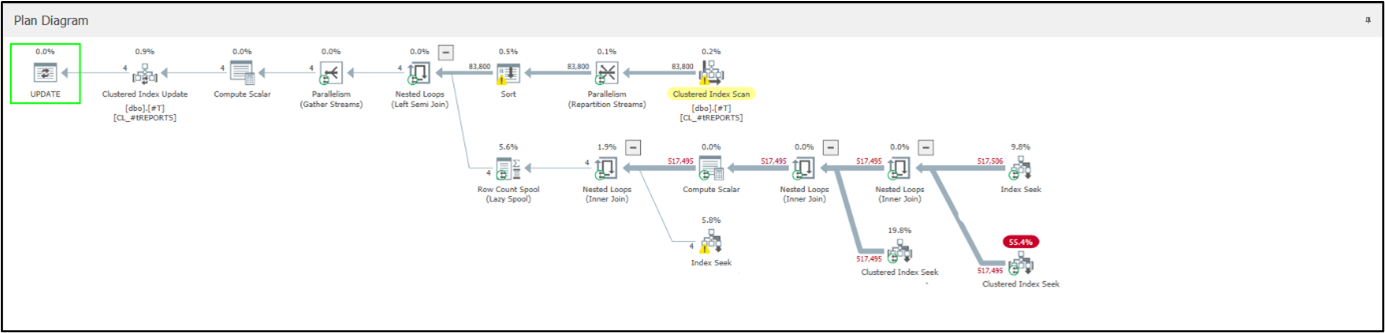
Figure 2 – 4: Plans of the refactored query. Significantly simpler, much easier to manage.
To summarise the outcome of our tuning here are a few figures describing the impact.
The total running time
Dropped from 4-6hrs to 1hr 50mins. After the changes the duration of the whole process is stable, and it rarely runs longer than 2 hours. Having a shorter duration means the process does not interfere with other processes running later at night or even in the early morning.
Plan costs
Initially, the costs of the plan were 31690. After the index changes and the refactoring, we ended with 3 plans of costs of 1518, 142 and 74. This is about 20 times less.
IO stats for one of the main table used in the major query that has been changed and at the end divided into one main and two simple queries;
Beyond the simple verification through the SQL agent history to check the running times we were able to see the drop in SMT as well. One of those options how to verify this was to compare the wait statistics from the period before and after the change.
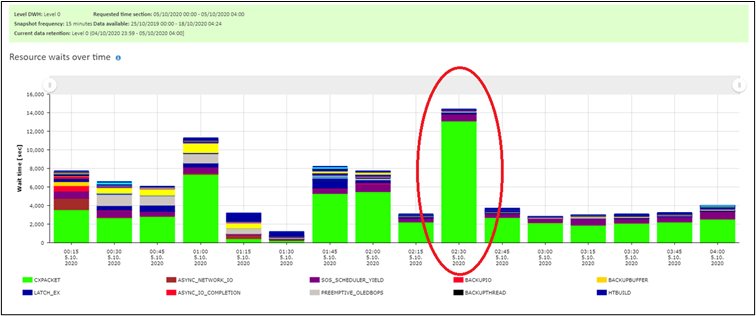
Figure 5: before waits statistics covering the time when the tuned process starts
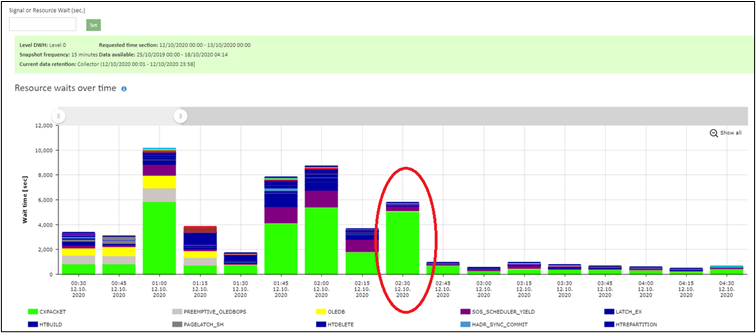
Figure 6: after waits statistics covering the time when the tuned process starts
We can see that after we tuned the process CXPACKET wait type dropped more than by half and also the following intervals of the waits on the server are smaller. The CXPACKET was here the most prevailing wait type because the process was so unnecessarily expensive
Final note; as part of our process all the changes were first suggested to our customer, who managed with their supplier to verify the logical changes and update the code in production where it has been proved to be working and useful.
Michal is a technically proficient SQL Server Specialist with a proven track record in resolving incidents and implementing changes within large-scale database infrastructures, ensuring maximum availability of services. Concurrently, as a Digital Content and Marketing Specialist, his priority is building strong online brand identities through strategic communication and creative storytelling. He consistently seeks new ways to enhance digital interaction, believing quality digital communication is key to success in today's connected world.
In the world of SQL Server, TEMPDB is often called the "public dumping ground." We expect it to be busy, but we also expect it to clean up after itself.
Read moreDear SMT users, We are glad to announce that a new version 00.6.00 is finally out.
Read more




