We recently resolved a critical performance issue where a client reported an unusual spike in HADR_SYNC_COMMIT wait types. This state indicated that transactions on the primary node were experiencing significant delays while waiting for hardening confirmations from the secondary node within an Always On Availability Group (AG).
Phase 1: Detailed Monitoring & Identification
To pinpoint the bottleneck, we implemented a three-tier testing strategy:
- AG Metrics Tracking: Using Performance Monitor and custom jobs logging to an SMT_Operations database, we collected data every 10 seconds on log_send_queue, redo_queue, and log transfer rates.
- Transaction Latency Testing: We created a dedicated job, SMT_Adhoc_InsertTest, which inserted a single 4-byte row into a dummy table every 10 seconds to measure the exact Round Trip Time (RTT) for a transaction commit.
- Internal SQL Module Analysis: We deployed an Extended Events (XEvents) session to track the start/finish times of internal SQL Server modules during the synchronization process.
The Findings: 595-Second Latencies
The evaluation revealed that the issue wasn't within SQL Server itself, but rather a massive throughput limitation in the network:
- Massive Log Queues: During nightly workloads (OxyImport/Export), the database generated logs at rates of 200 MB/s. This flooded the log_send_queue with gigabytes of data. Because log blocks are synchronized sequentially, even a tiny 1-row insert had to wait for the entire queue ahead of it to be hardened on the secondary.
- Extreme Wait Times: While daytime latencies hovered between 500ms and 4s, nightly peaks reached staggering values of 595 seconds. Total daily HADR_SYNC_COMMIT waits reached 800,000 seconds.
- Bottleneck Localization: XEvents confirmed that the longest waits occurred during Primary-Send and Primary-RemoteHarden.
Root Cause: The "100 Mbit" Trap
A physical infrastructure audit revealed that 2 out of 4 paths to the secondary node had downgraded to 100 Mbit speed. Furthermore, since the AG Endpoints were configured using FQDNs resolving to Public IPs, the SQL traffic was routing through the "Public" interface (Team #1) instead of the intended high-speed Private team (Team #2).
.png)
.png)
Proposed Solutions & Final Implementation
We presented the client with two options:
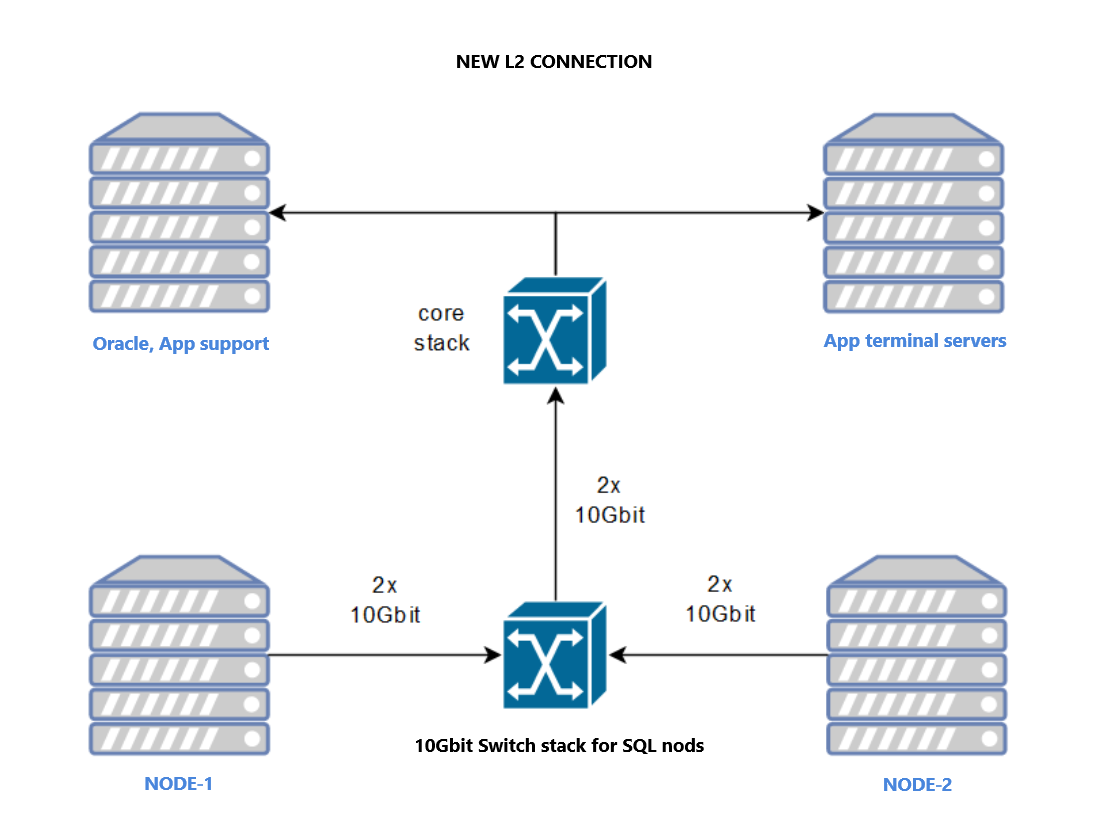
- Hybrid Solution (4x1Gbit + 2x10Gbit): Forcing sync traffic through a private interface via hosts file entries to ensure redundancy and performance separation.
- Consolidated 10Gbit Solution: Moving all traffic (Sync, Heartbeat, Client) to a robust 10Gbit infrastructure.
The client chose Option 2. Combined with a core switch upgrade, the 4x1Gbit links were decommissioned, and the nodes were connected via 2x10Gbit interfaces to dedicated Dell switches using an untagged VLAN for internal cluster traffic.
Conclusion
Post-implementation, the HADR_SYNC_COMMIT wait times dropped to zero. This case serves as a reminder: even the most optimized SQL Server instance cannot outperform a degraded or misconfigured network layer.






